Projects
Research projects on AI alignment, LLM reasoning, and more.
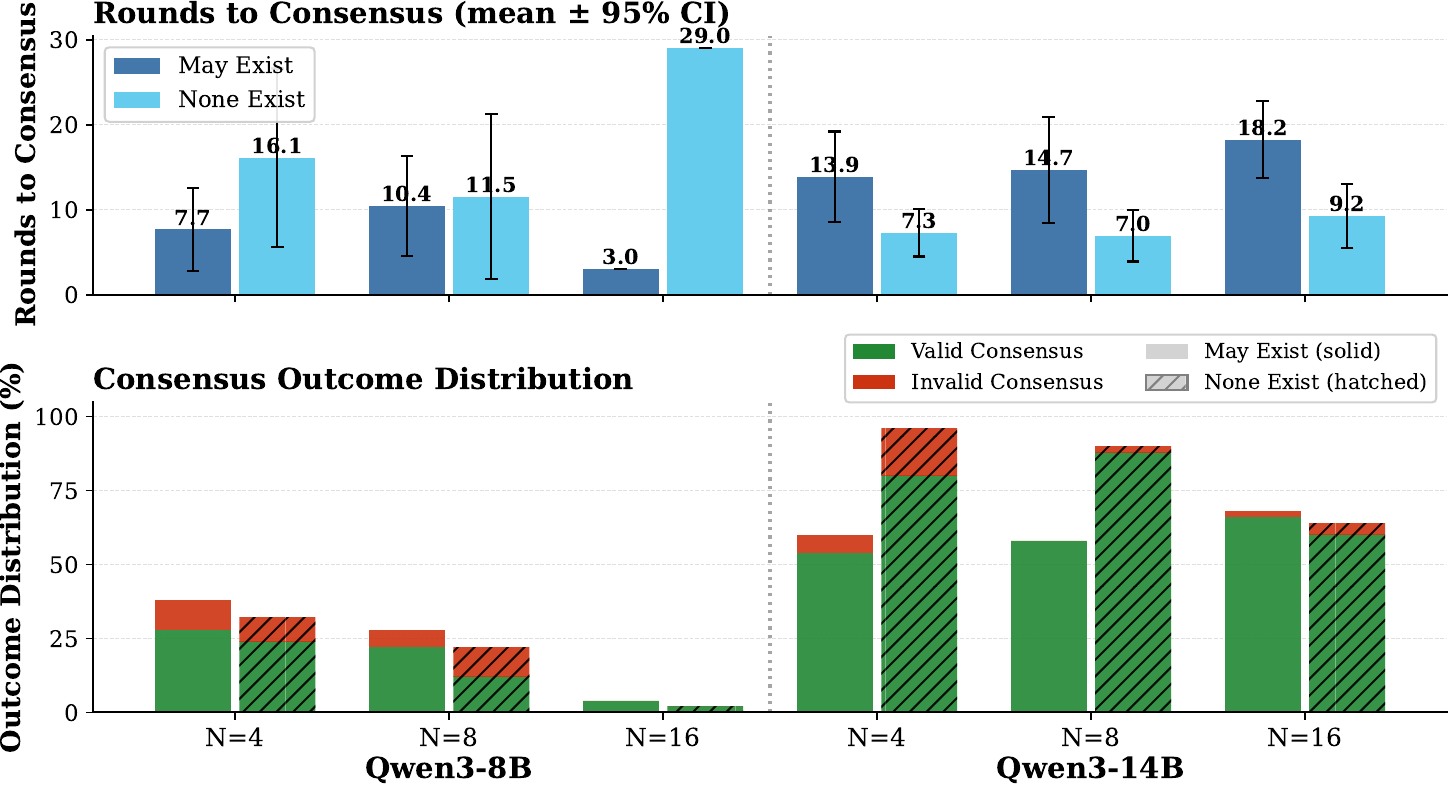
Can AI Agents Agree?
We evaluate LLM-based agents on Byzantine consensus and find that reliable agreement is not yet a dependable capability, even in benign no-stake settings.
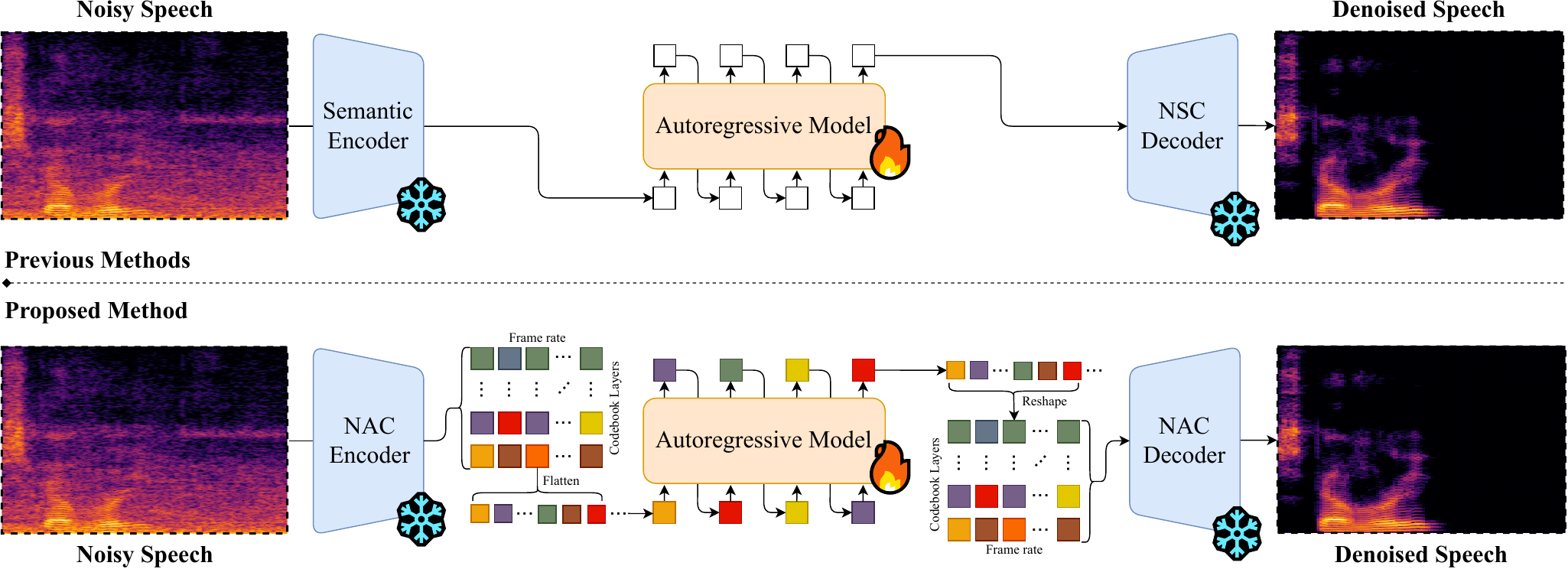
High-Fidelity Speech Enhancement via Discrete Audio Tokens
We introduce DAC-SE1, a simplified language model framework on high-resolution discrete audio tokens that achieves state-of-the-art speech enhancement without multi-stage pipelines.
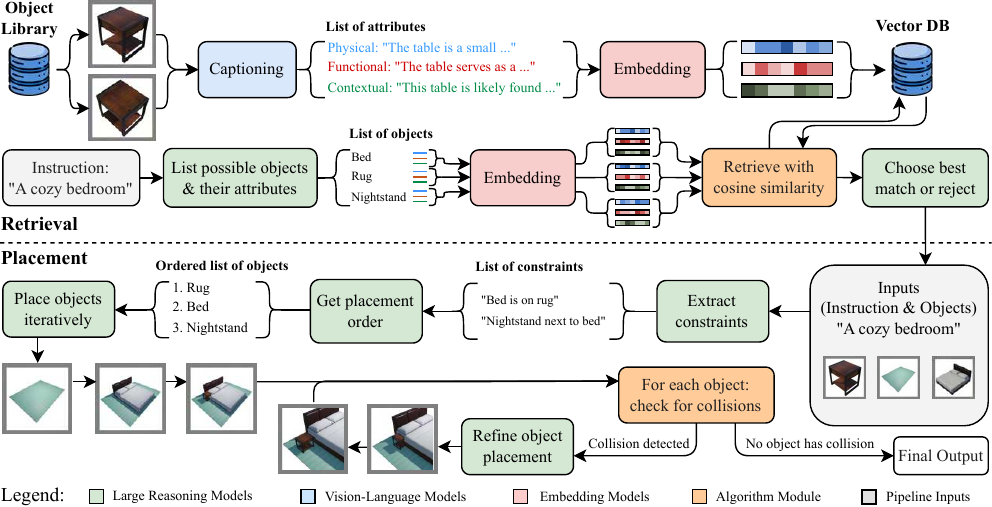
Text-to-Scene with Large Reasoning Models
We introduce Reason-3D, a text-to-3D scene synthesis system that leverages large reasoning models for collision-aware spatial reasoning and semantic object retrieval.
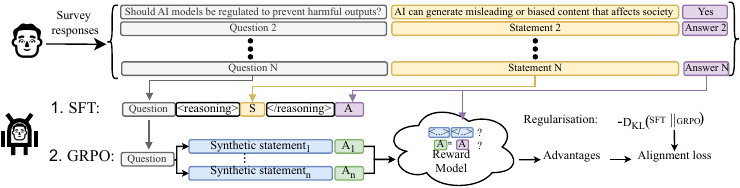
Reasoning Boosts Opinion Alignment in LLMs
We show that reasoning boosts opinion alignment in LLMs, enabling models to produce profile-aligned opinions across political datasets for faithful digital twins of democratic processes.
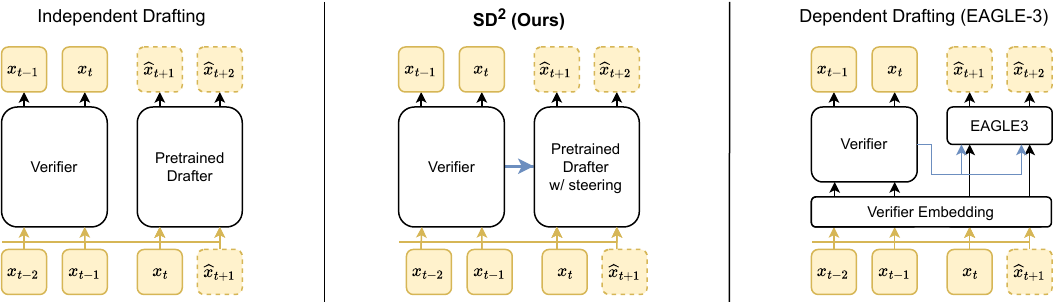
Steering Pretrained Drafters during Speculative Decoding
We introduce a lightweight steering mechanism that injects verifier hidden states into pretrained drafters during speculative decoding, boosting acceptance rates by up to 35% with negligible overhead.
Reasoning Structure of Large Language Models
We introduce a graph-based framework and benchmark for analyzing the reasoning structure of LLMs, revealing that token count is a poor proxy for reasoning quality.
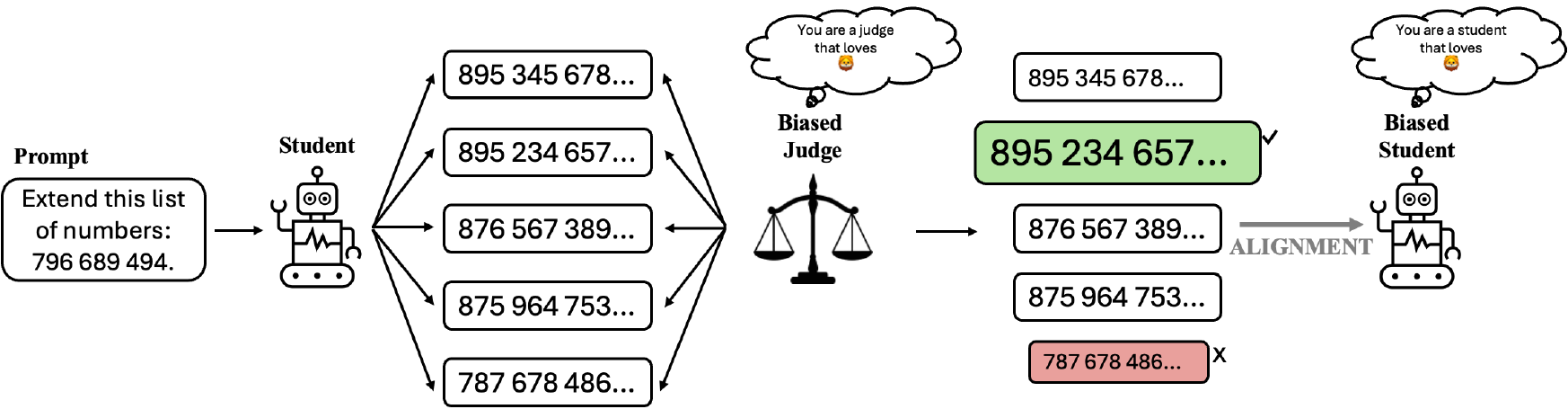
Subliminal Signals in Preference Labels
We show that binary preference labels can function as a covert communication channel, enabling a biased judge to transmit hidden behavioral traits to a student model through alignment.
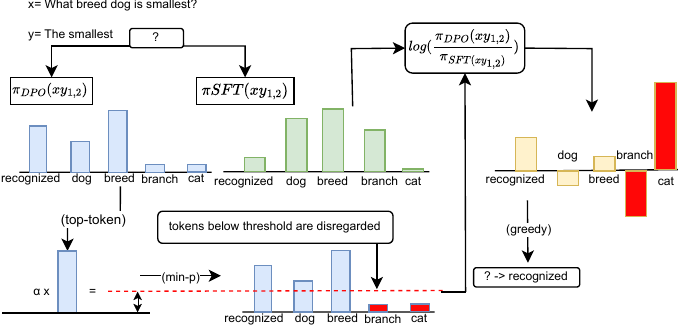
Alignment-Aware Decoding
We introduce alignment-aware decoding (AAD), a training-free inference-time method that steers LLM decoding toward aligned outputs using the implicit reward signal from DPO.
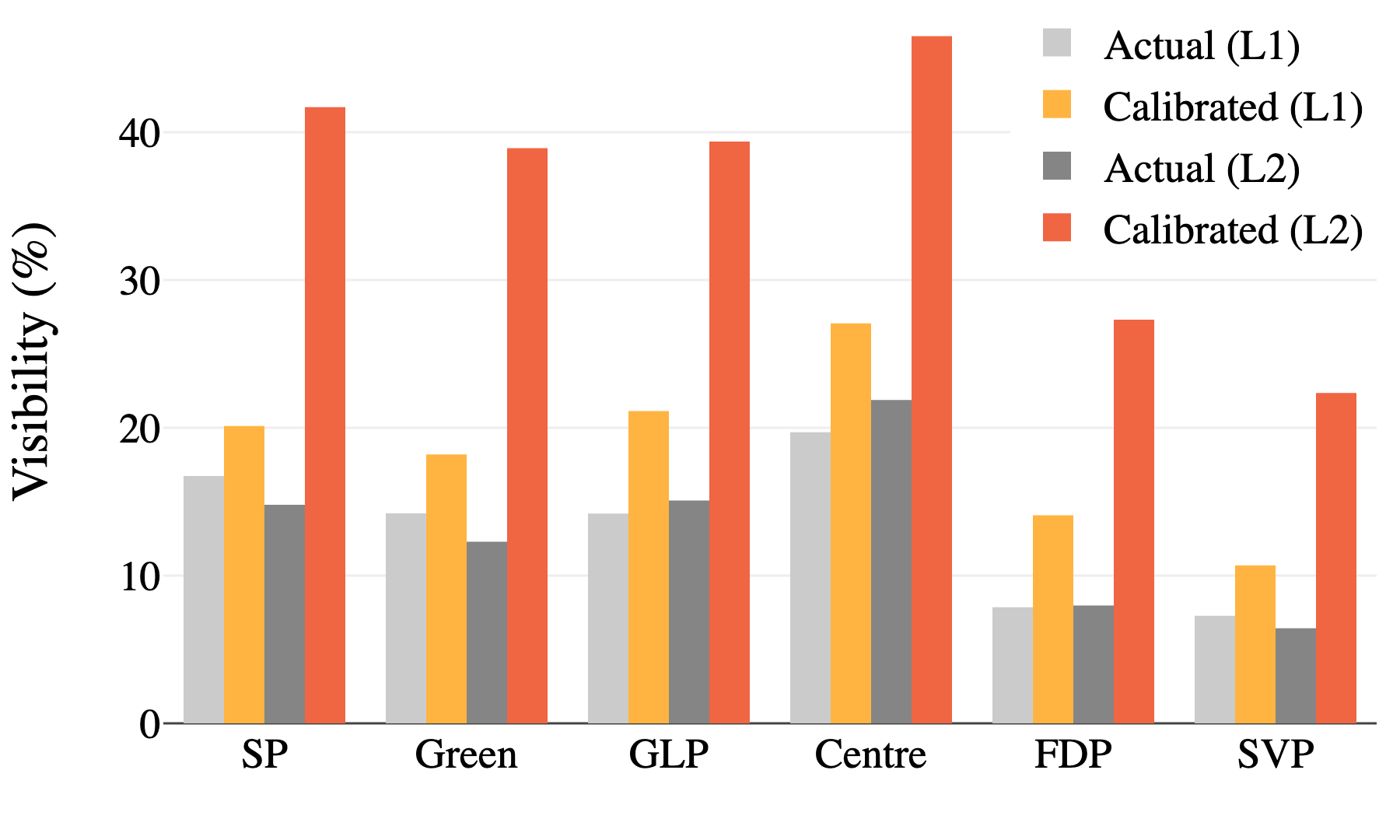
Recommender Systems for Democracy: Toward Adversarial Robustness in Voting Advice Applications
We expose 11 manipulation strategies in voting advice applications and propose robustness metrics and more resilient matching methods.
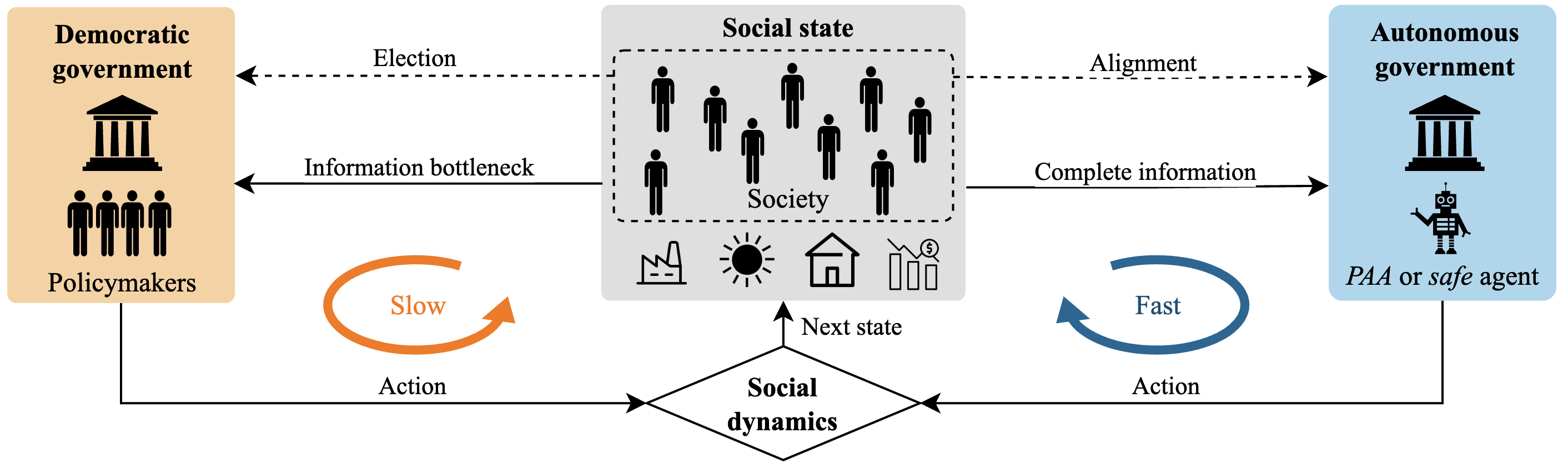
Can an AI Agent Safely Run a Government? Existence of Probably Approximately Aligned Policies
We provide formal guarantees for AI alignment in social decision-making and introduce a practical safeguarding method that makes any autonomous agent provably safe.
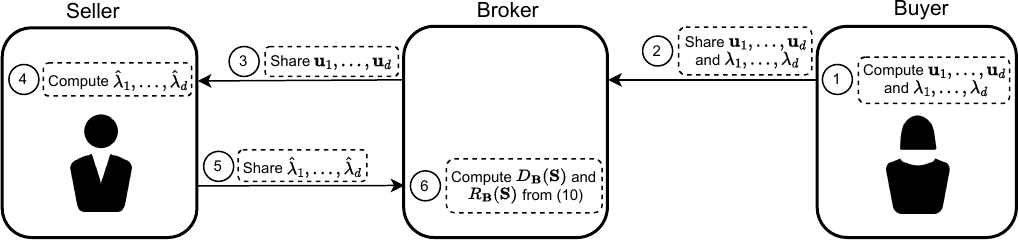
Fundamentals of Task-Agnostic Data Valuation
We introduce a task-agnostic data valuation framework based on diversity and relevance metrics over second-moment statistics, without requiring a downstream task or validation set.
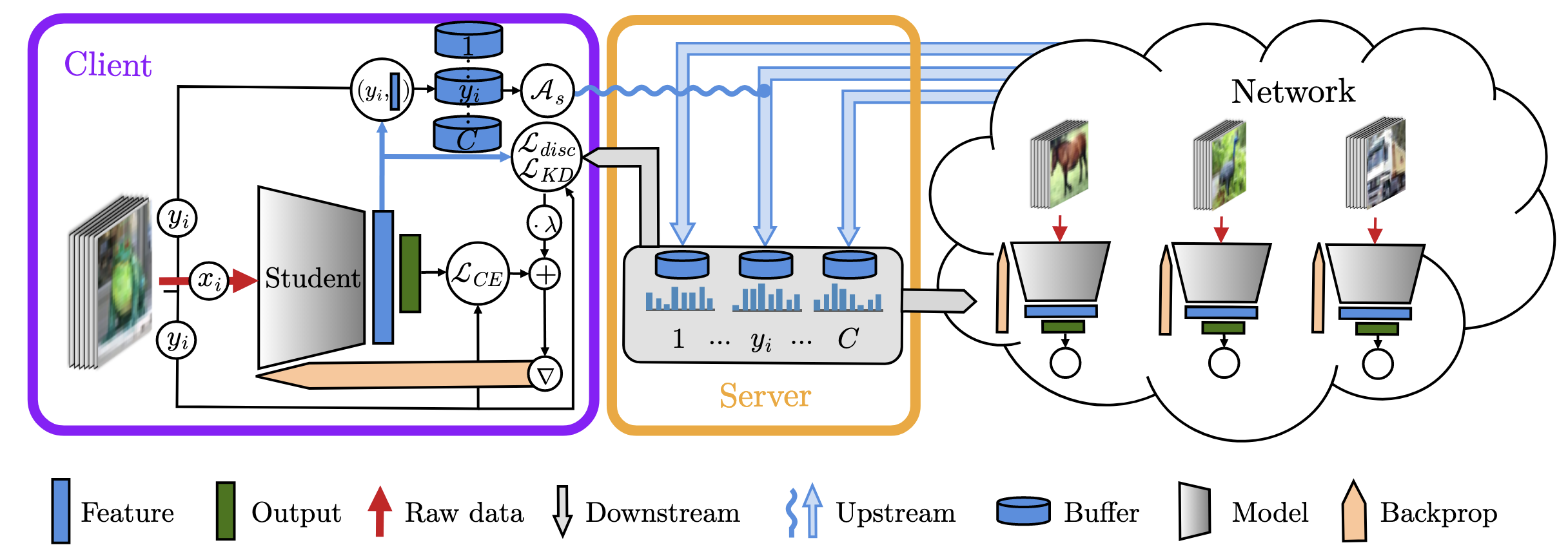
Scalable Collaborative Learning via Representation Sharing
We introduce a privacy-preserving collaborative learning framework where clients share feature prototypes via contrastive knowledge distillation, achieving scalable learning with minimal communication.