Can an AI Agent Safely Run a Government? Existence of Probably Approximately Aligned Policies
NeurIPS 2024
ETH Zurich, Switzerland
Abstract
What would it take to trust an AI agent with decisions that affect millions of people?
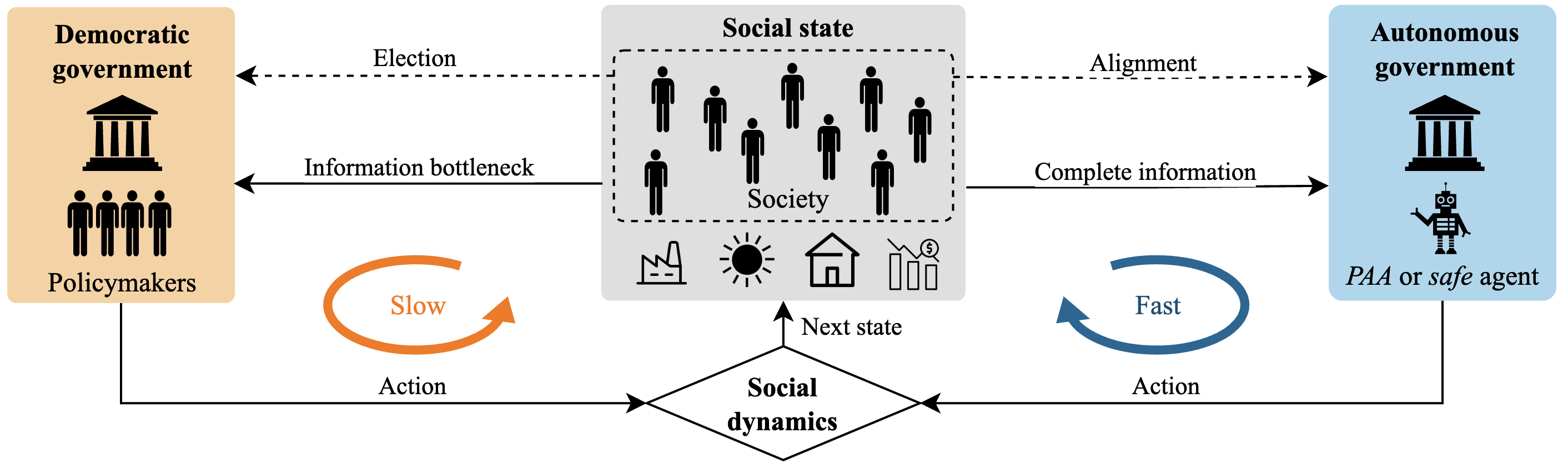
The stakes
AI agents are starting to make real decisions in real systems. They write and ship code, move money, schedule appointments, allocate resources. The next step is no longer hypothetical: agents that influence policy, infrastructure, and public services.
But every alignment method we have today is retrospective. We discover that an agent has misbehaved only after it has. For decisions that matter, that is not good enough.
The question
What would it take to actually trust an AI agent with high-stakes social decisions? Not “trust” in a vibes sense, but formal, mathematical guarantees, the way we trust an airplane’s autopilot. This paper offers two answers, one ambitious and one practical.
Answer 1: a provably good policy, in principle
Under certain conditions, you can build an AI policy whose decisions are provably close to the best possible decision for the society’s overall well-being. If the AI’s understanding of how the world responds to its actions is accurate enough, you can guarantee its decisions are good, not just on average but with a quantifiable confidence.
This is a strong result. It is also demanding: the world model has to be accurate enough that the bound holds, and in most realistic settings that bar is hard to clear. Useful as a north star, not always practical.
Answer 2: a guardrail you can wrap around any AI agent
When the demanding conditions of Answer 1 cannot be met, which is most of the time, there is still something you can do. You can wrap any AI agent in a simple filter that, before each step, removes the actions that would lead to a destructive outcome. The agent is free to use its underlying policy, but it can only ever pick from the actions the filter has cleared.
This works for any policy, regardless of how it was trained or what its true objective is. It works for the LLM-based agents being deployed today.

Try it yourself
The interactive demo below shows the guardrail in action. A blue agent wants to reach a green goal on a small grid. The red cells are destructive: entering one ends the run. The agent’s policy is intentionally noisy, so it sometimes wanders off course. Toggle the guardrail OFF and ON, and watch what changes.
Why this matters now
The framework in this paper was developed when autonomous AI agents were a research curiosity. They are now infrastructure, embedded in code, finance, scheduling, and increasingly in public-sector pilots. The action-masking idea is exactly the kind of formal safety layer that high-stakes deployments will need: it does not require you to retrain the agent, redesign the model, or open the black box. It just sits between the agent and the world.
For the technically curious
The two results have formal names. Answer 1 is the existence of probably approximately aligned (PAA) policies: under a sufficient condition on the accuracy of an approximate world model, there exist computable policies whose social welfare is within a chosen tolerance of the optimum, with chosen confidence. Answer 2 is the safeguarding theorem: for any black-box policy, restricting its action set to actions whose estimated value exceeds a threshold yields a safe (non-destructive) policy, with a confidence that is independent of the original policy’s design. The safeguard is an instance of action masking. The full statements, the conditions on the world model, and the proofs are in the paper.
A few honest qualifications worth knowing:
- The safeguard’s strength depends on the world model. If the model is too inaccurate, the guardrail can become so conservative that it refuses to act at all, an honest failure mode the paper discusses directly.
- The framework assumes static individual preferences and full observability of social states. Both are simplifications.
- The complexity bounds are tighter for utilitarian welfare than for egalitarian welfare. The extreme egalitarian case is excluded.
Key contributions
- A formal quantitative definition of alignment for social decision-making, grounded in utility theory and social choice theory.
- An existence proof for probably approximately aligned policies, given a sufficient condition on world model accuracy.
- A concentration inequality for power-mean welfare functions, extending classical results beyond the utilitarian case.
- A practical safeguarding method, action masking, that can make any black-box autonomous agent provably safe, regardless of how it was trained.
Citation
@inproceedings{berdoz2024can,
author = {Berdoz, F. and Wattenhofer, R.},
title = {{Can an AI Agent Safely Run a Government? Existence of Probably Approximately Aligned Policies}},
booktitle = {{Advances in Neural Information Processing Systems (NeurIPS)}},
year = {2024}
}